Paragraph Vector学习笔记
什么是Paragraph Vector
paragraph vector是word vector的扩展,word vector是将一个词表示为一个实数向量,paragraph vector是将一串文本表示为一个实数向量,这个文本可以是一句话,一个段落或者完整的文章。和word vector达到的类似效果是,有了这样的实数向量表示,做文章的相似度比较就变得简单了,基于这个我们就可以做文本分类。和传统的词袋模型(BOW model)相比,这个方法客服了两个词袋模型的缺点:
- 不考虑词之间的顺序
- 不考虑词的语义
论文原文abstract部分是这样描述的:
Many machine learning algorithms require the input to be represented as a fixed-length feature vector. When it comes to texts, one of the most common fixed-length features is bag-of-words. Despite their popularity, bag-of-words features have two major weaknesses: they lose the ordering of the words and they also ignore semantics of the words. For example, “powerful,” “strong” and “Paris” are equally distant. In this paper, we propose Paragraph Vector, an unsupervised algorithm that learns fixed-length feature representations from variable-length pieces of texts, such as sentences, paragraphs, and documents. Our algorithm represents each document by a dense vector which is trained to predict words in the document. Its construction gives our algorithm the potential to overcome the weaknesses of bag-of-words models. Empirical results show that Paragraph Vectors outperform bag-of-words models as well as other techniques for text representations. Finally, we achieve new state-of-the-art results on several text classification and sentiment analysis tasks.
Deeplearning4j中对Doc2Vec是这样描述的,这里的Doc2Vec和Paragraph Vector是一个概念,不过deeplearning4j中的实现是用来直接做分类的,论文中的分类和paragraph vector是两个层次的概念,paragraph vector仅仅负责生成实数向量,然后通过某一个传统的分类器如svm,logistic regression,knn来做分类,deeplearning4j的实现是把分类直接做进去了,具体下文会再介绍
The main purpose of Doc2Vec is associating arbitrary documents with labels, so labels are required. Doc2vec is an extension of word2vec that learns to correlate labels and words, rather than words with other words.
原理介绍
论文中提到的两个模型都是基于word vector衍生而来,所以建议先阅读word2vec的blog或者相关论文
PV-DM
这个模型和word vector中的CBOW非常相似,区别在于在输入层增加了一个paragraph token/id作为输入,这个输入也有单独的权重矩阵D,网络结构参看下图
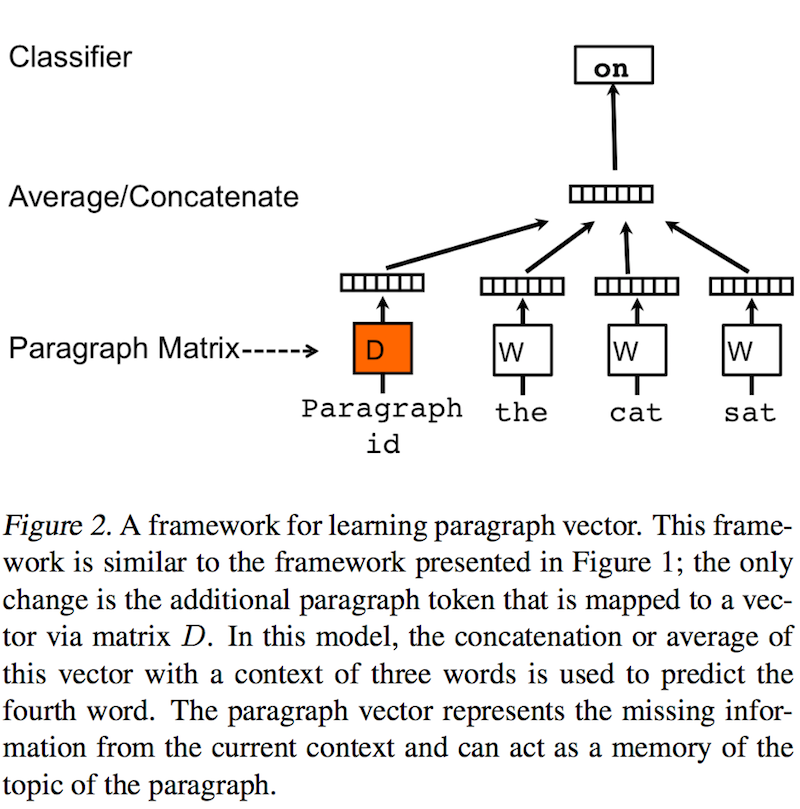
训练的方法和word vector没有什么不同,forward and backpropagation with gradient, 预测时,和word vector不同,word vector计算完就变成一个查询的hash表了,用word去查询对应的实数向量即可,paragraph vector当做预测时,一个新的paragraph要经过inference step(具体原理和实现我也没弄明白)才能获得其对应的实数向量,这个inference过程也是用的梯度下降。
PV-DBOW
这个模型和word vector中的skip-gram很像, 输入是paragraph id(这个我没明白具体实现中是不是类似word one-hot的表示,但考虑paragraph的规模是不确定的,one-hot也表示不了,弄明白了回来更新吧),输出是paragraph中的一个小的滑动窗口,按照论文中表述这个模型不需要word vector,因为网络结构中也根本就没有这一层,学习到的只有paragraph vector的表示,但论文建议综合PV-DM和PV-DBOW会有更好的效果,但如何combine没讲,是weighted mean还是sum没有明确说,就提到combine的效果会更好,并且说了单独PV-DM的效果也足够好了。

有哪些使用场景
- 文本分类(情感分析)
- information retrieval(score排序)
- spam filter(实际上也是分类问题)
目前我正在验证将其用在短文本意图识别中。
一些不同的声音
由于目前我也没有做充分的实验来验证paragraph vector到底效果如何,有结论来更新,目前在一些讨论中也有对这个问题的议论,供参考
- word2vec和sentence2vec的真正差别是什么?后者和简单用词向量累加有什么差别?
- doc2vec实战效果
- How to get vector for a sentence from the word2vec of tokens in sentence
There are differet methods to get the sentence vectors :
- Doc2Vec : you can train your dataset using Doc2Vec and then use the sentence vectors.
- Average of Word2Vec vectors : You can just take the average of all the word vectors in a sentence. This average vector will represent your sentence vector.
- Average of Word2Vec vectors with TF-IDF : this is one of the best approach which I will recommend. Just take the word vectors and multiply it with their TF-IDF scores. Just take the average and it will represent your sentence vector.
DeepLearning4J ParagraphVectors使用
目前初步测试了下,小规模短文本效果不理想,大规模的短文本正在验证,并且存在一个问题在某些场景下就是缺少大量的标注样本的,这时候如何通过基础的非标注语料(解决word vector的准确性问题)和获取的少量标注样本(解决短文本分类)互补是个问题,目前还没有好的解决方法,关于这个问题也在github上提了一个issue
TokenizerFactory tokenizerFactory = new DefaultTokenizerFactory();
tokenizerFactory.setTokenPreProcessor(new CommonPreprocessor());
List<LabelledDocument> labelledDocumentList = ...load you data here...;
LabelAwareIterator labelAwareIterator = new SimpleLabelAwareIterator(labelledDocumentList);
ParagraphVectors paragraphVectors = new ParagraphVectors.Builder()
.learningRate(0.025)
.minWordFrequency(1)
.minLearningRate(0.001)
.batchSize(1000)
.layerSize(100)
.epochs(20)
.trainSequencesRepresentation(true)
.trainElementsRepresentation(true)
.windowSize(5)
.iterate(labelAwareIterator)
.labelsSource(labelAwareIterator.getLabelsSource())
.tokenizerFactory(tokenizerFactory)
.build();
paragraphVectors.fit();
paragraphVectors.nearestLabels("...test sentence here...")deeplearning4j使用可以从它的quickstart文档开始